Characterizing User Content on a Multi-lingual Social Network
Abstract
Social media has been on the vanguard of political information diffusion in the 21st century. Most studies that look into disinformation, political influence and fake-news focus on mainstream social media platforms. This has inevitably made English an important factor in our current understanding of political activity on social media. As a result, there have been a very limited number of representative studies on a large section of the democratic world, including the largest, multilingual and multicultural democracy: India. In this paper we present our characterisation of a multilingual social network in India called ShareChat. We collect an exhaustive dataset across 72 weeks before and during the Indian general elections of 2019, across 14 languages. We investigate the cross lingual dynamics by clustering visually similar images together, and exploring how they move across language barriers. We find that Telugu, Malayalam, Tamil and Kannada languages tend to be dominant in soliciting political memes and images, and posts from Hindi (and images having text in English) have the largest cross-lingual diffusion across ShareChat. In the case of memes that cross language barriers, we see that language translation is used to widen the accessibility. That said, we find cases where the same image is associated with very different text (and therefore meanings). This initial characterisation paves the way for more advanced pipelines to understand the dynamics of fake and political content in a multi-lingual and non-textual setting.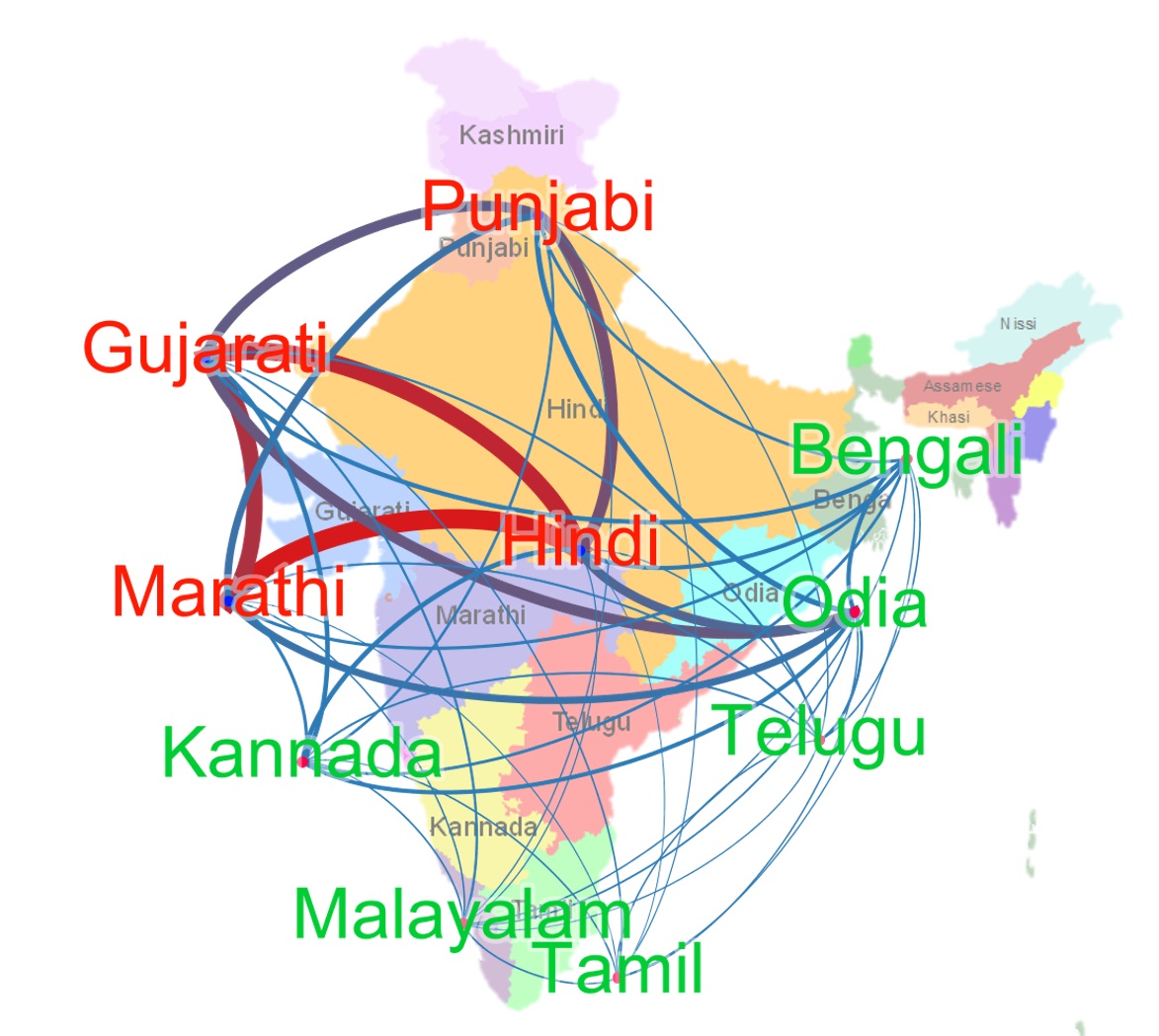
Multilingual Dataset
An anonymized version of the dataset used in our paper is available for the research community. If you are interested in using this data, please send us an email according to the Request Data section and indicate which of following parts you need in the email.
Posts Dataset: In CSV format, contains information like posts index, type of posts, language forum etc. of Sharechat posts.
-
Images Dataset: In CSV format, contains Image Index, cluster IDs, image hashes computed from PDQ clustering.
You can find the format of the dataset from here.
Contact Us
If you are interested in using this data, please fill the form to to get the link where you can download the data.
We are sharing the dataset under the terms and conditions specified here and following Twitter's Terms of Usage. Please note that submitting the form indicates that you accept the terms and conditions of the data. In the form, please indicate which part of the dataset you need. If you do not get any email notification for your logged request within 24 hours, please e-mail us at netsys.noreply[at]gmail.com.Dataset Terms and Conditions
You will use the data solely for the purpose of non-profit research or non-profit education.
You will respect the privacy of end users and organizations that may be identified in the data. You will not attempt to reverse engineer, decrypt, de-anonymize, derive or otherwise re-identify anonymized information.
You will not distribute the data beyond your immediate research group.
If you create a publication using our datasets, please cite our papers as follows.
@inproceedings{agarwal2020characterising,
title={Characterising User Content on a Multi-lingual Social Network},
author={Agarwal, Pushkal and Garimella, Kiran and Joglekar, Sagar and Sastry, Nishanth and Tyson, Gareth},
booktitle={Proceedings of the International AAAI Conference on Web and Social Media},
volume={14},
pages={2--11},
year={2020}
}